This is the multi-page printable view of this section. Click here to print.
0.1.x
- 1: Overview
- 2: User
- 2.1: Autoscaling
- 2.2: Slurm
- 3: Dev
- 3.1: Architecture
- 3.2: Cluster Control
- 3.3: Develop
- 3.4: NodeSet Controller
- 4: Quickstart Guides
1 - Overview
slurm-operator
This project provides a framework that runs Slurm in Kubernetes.
Overview
This project deploys Slurm on Kubernetes. These pods coexist with other running workloads on Kubernetes. This project provides controls over the Slurm cluster configuration and deployment, along with configurable autoscaling policy for Slurm compute nodes.
This project allows for much of the functionality within Slurm for workload management. This includes:
- Priority scheduling: Determine job execution order based on priorities and weights such as age
- Fair share: Resources are distributed equitably among users based on historical usage.
- Quality of Service (QoS): set of policies, such as limits of resources, priorities, and preemption and backfilling.
- Job accounting: Information for every job and job step executed
- Job dependencies: Allow users to specify relationships between jobs, from start, succeed, fail, or a particular state.
- Workflows with partitioning: Divide cluster resource into sections for job management
To best enable Slurm in Kubernetes, the project uses Custom Resources (CRs) and an Operator to extend Kubernetes with custom behaviors for Slurm clusters. In addition, Helm is used for managing the deployment of the various components of this project to Kubernetes.
Supported Slurm Versions
Slurm 24.05 Data parsers v40, v41
Quickstart
See the Quickstart Guide to install.
Overall Architecture
This is a basic architecture. A more in depth description can be found in the docs directory.

Known Issues
- CGroups is currently disabled, due to difficulties getting core information into the pods.
- Updates may be slow, due to needing to wait for sequencing before the slurm-controller can be deployed.
License
Copyright (C) SchedMD LLC.
Licensed under the Apache License, Version 2.0 you may not use project except in compliance with the license.
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an “AS IS” BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
2 - User
2.1 - Autoscaling
The slurm-operator may be configured to autoscale NodeSets pods based on Slurm metrics. This guide discusses how to configure autoscaling using KEDA.
Getting Started
Before attempting to autoscale NodeSets, Slinky should be fully deployed to a Kubernetes cluster and Slurm jobs should be able to run.
Dependencies
Autoscaling requires additional services that are not included in Slinky. Follow documentation to install Prometheus, Metrics Server, and KEDA.
Prometheus will install tools to report metrics and view them with Grafana. The
Metrics Server is needed to report CPU and memory usage for tools like
kubectl top. KEDA is recommended for autoscaling as it provides usability
improvements over standard the Horizontal Pod Autoscaler (HPA).
To add KEDA in the helm install, run
helm repo add kedacore https://kedacore.github.io/charts
Install the slurm-exporter. This chart is installed as a dependency of the slurm helm chart by default. Configure using helm/slurm/values.yaml.
Verify KEDA Metrics API Server is running
$ kubectl get apiservice -l app.kubernetes.io/instance=keda
NAME SERVICE AVAILABLE AGE
v1beta1.external.metrics.k8s.io keda/keda-operator-metrics-apiserver True 22h
KEDA provides the metrics apiserver required by HPA to scale on custom metrics from Slurm. An alternative like Prometheus Adapter could be used for this, but KEDA offers usability enhancements and improvements to HPA in addition to including a metrics apiserver.
Autoscaling
Autoscaling NodeSets allows Slurm partitions to expand and contract in response to the CPU and memory usage. Using Slurm metrics, NodeSets may also scale based on Slurm specific information like the number of pending jobs or the size of the largest pending job in a partition. There are many ways to configure autoscaling. Experiment with different combinations based on the types of jobs being run and the resources available in the cluster.
NodeSet Scale Subresource
Scaling a resource in Kubernetes requires that resources such as Deployments and StatefulSets support the scale subresource. This is also true of the NodeSet Custom Resource.
The scale subresource gives a standard interface to observe and control the
number of replicas of a resource. In the case of NodeSet, it allows Kubernetes
and related services to control the number of slurmd replicas running as part
of the NodeSet.
Note: NodeSets with replicas: null are intended to scale similar to a
DaemonSet. This is not an appropriate type of NodeSet to use with Autoscaling as
the Slinky operator will handle scaling NodeSet replicas across the cluster
based on the selection criteria.
To manually scale a NodeSet, use the kubectl scale command. In this example,
the NodeSet (nss) slurm-compute-radar is scaled to 1.
$ kubectl scale -n slurm nss/slurm-compute-radar --replicas=1
nodeset.slinky.slurm.net/slurm-compute-radar scaled
$ kubectl get pods -o wide -n slurm -l app.kubernetes.io/instance=slurm-compute-radar
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
slurm-compute-radar-p8jwh 1/1 Running 0 2m48s 10.244.4.17 kind-worker <none> <none>
This corresponds to the Slurm partition radar.
$ kubectl exec -n slurm statefulset/slurm-controller -- sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
radar up infinite 1 idle kind-worker
NodeSets may be scaled to zero. In this case, there are no replicas of slurmd
running and all jobs scheduled to that partition will remain in a pending state.
$ kubectl scale nss/slurm-compute-radar -n slurm --replicas=0
nodeset.slinky.slurm.net/slurm-compute-radar scaled
For NodeSets to scale on demand, an autoscaler needs to be deployed. KEDA allows resources to scale from 0<->1 and also creates an HPA to scale based on scalers like Prometheus and more.
KEDA ScaledObject
KEDA uses the Custom Resource ScaledObject to monitor and scale a resource. It will automatically create the HPA needed to scale based on external triggers like Prometheus. With Slurm metrics, NodeSets may be scaled based on data collected from the Slurm restapi.
This example ScaledObject will watch the number of jobs pending for the
partition radar and scale the NodeSet slurm-compute-radar until a threshold
value is satisfied or maxReplicaCount is reached.
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: scale-radar
spec:
scaleTargetRef:
apiVersion: slinky.slurm.net/v1alpha1
kind: NodeSet
name: slurm-compute-radar
idleReplicaCount: 0
minReplicaCount: 1
maxReplicaCount: 3
triggers:
- type: prometheus
metricType: Value
metadata:
serverAddress: http://prometheus-kube-prometheus-prometheus.prometheus:9090
query: slurm_partition_pending_jobs{partition="radar"}
threshold: "5"
Note: The Prometheus trigger is using metricType: Value instead of the
default AverageValue. AverageValue calculates the replica count by averaging
the threshold across the current replica count.
Check [ScaledObject] documentation for a full list of allowable options.
In this scenario, the ScaledObject scale-radar will query the Slurm metric
slurm_partition_pending_jobs from Prometheus with the label
partition="radar".
When there is activity on the trigger (at least one pending job), KEDA will
scale the NodeSet to minReplicaCount and then let HPA handle scaling up to
maxReplicaCount or back down to minReplicaCount. When there is no activity
on the trigger after a configurable amount of time, KEDA will scale the NodeSet
to idleReplicaCount. See the KEDA documentation on idleReplicaCount for
more examples.
Note: The only supported value for idleReplicaCount is 0 due to
limitations on how the HPA controller works.
To verify a KEDA ScaledObject, apply it to the cluster in the appropriate namespace on a NodeSet that has no replicas.
$ kubectl scale nss/slurm-compute-radar -n slurm --replicas=0
nodeset.slinky.slurm.net/slurm-compute-radar scaled
Wait for Slurm to report that the partition has no nodes.
$ slurm@slurm-controller-0:/tmp$ sinfo -p radar
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
radar up infinite 0 n/a
Apply the ScaledObject using kubectl to the correct namespace and verify the
KEDA and HPA resources are created.
$ kubectl apply -f scaledobject.yaml -n slurm
scaledobject.keda.sh/scale-radar created
$ kubectl get -n slurm scaledobjects
NAME SCALETARGETKIND SCALETARGETNAME MIN MAX TRIGGERS AUTHENTICATION READY ACTIVE FALLBACK PAUSED AGE
scale-radar slinky.slurm.net/v1alpha1.NodeSet slurm-compute-radar 1 5 prometheus True False Unknown Unknown 28s
$ kubectl get -n slurm hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
keda-hpa-scale-radar NodeSet/slurm-compute-radar <unknown>/5 1 5 0 32s
Once the [ScaledObject] and HPA are created, initiate some jobs to test that
the NodeSet scale subresource is scaled in response.
$ sbatch --wrap "sleep 30" --partition radar --exclusive
The NodeSet will scale to minReplicaCount in response to activity on the
trigger. Once the number of pending jobs crosses the configured threshold
(submit more exclusive jobs to the partition), more replicas will be created to
handle the additional demand. Until the threshold is exceeded, the NodeSet
will remain at minReplicaCount.
Note: This example only works well for single node jobs, unless threshold
is set to 1. In this case, HPA will continue to scale up NodeSet as long as
there is a pending job until up until it reaches the maxReplicaCount.
After the default coolDownPeriod of 5 minutes without activity on the trigger,
KEDA will scale the NodeSet down to 0.
2.2 - Slurm
Slurm
Slurm is an open source, fault-tolerant, and highly scalable cluster management and job scheduling system for large and small Linux clusters. Slurm requires no kernel modifications for its operation and is relatively self-contained. As a cluster workload manager, Slurm has three key functions. First, it allocates exclusive and/or non-exclusive access to resources (compute nodes) to users for some duration of time so they can perform work. Second, it provides a framework for starting, executing, and monitoring work (normally a parallel job) on the set of allocated nodes. Finally, it arbitrates contention for resources by managing a queue of pending work. Optional plugins can be used for accounting, advanced reservation, gang scheduling (time sharing for parallel jobs), backfill scheduling, topology optimized resource selection, resource limits by user or bank account, and sophisticated multifactor job prioritization algorithms.
Architecture
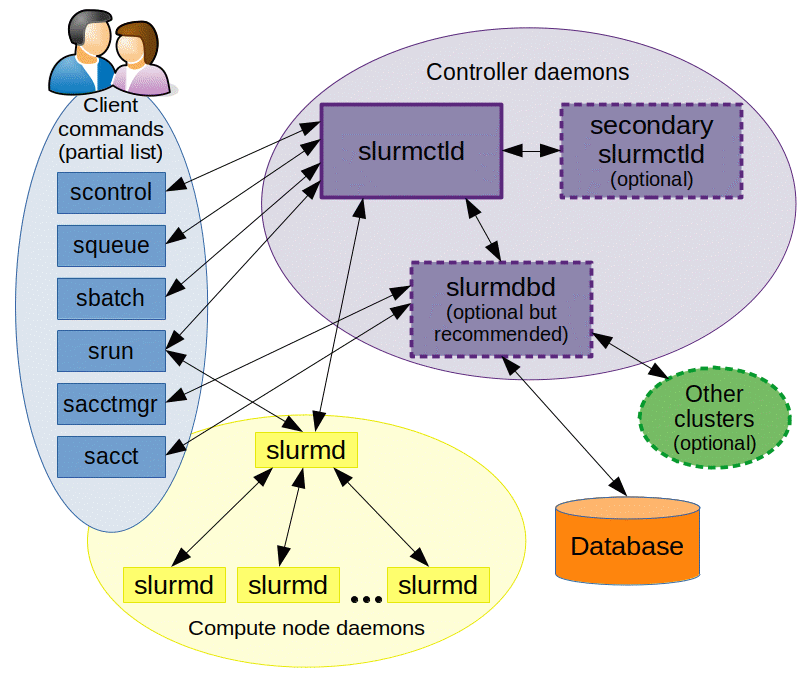
See the Slurm architecture docs for more information.
3 - Dev
3.1 - Architecture
Overview
This document describes the high-level architecture of the Slinky
slurm-operator.
Big Picture
The slurm-operator follows the Kubernetes operator
pattern.
Operators are software extensions to Kubernetes that make use of custom resources to manage applications and their components. Operators follow Kubernetes principles, notably the control loop.
The slurm-operator has one controller for each Custom Resource Definition
(CRD) that it is responsible to manage. Each controller has a control loop where
the state of the Custom Resource (CR) is reconciled.
Often, an operator is only concerned about data reported by the Kubernetes API.
In our case, we are also concerned about data reported by the Slurm API, which
influences how the slurm-operator reconciles certain CRs.
Directory Map
This project follows the conventions of:
api/
Contains Custom Kubernetes API definitions. These become Custom Resource Definitions (CRDs) and are installed into a Kubernetes cluster.
cmd/
Contains code to be compiled into binary commands.
config/
Contains yaml configuration files used for kustomize deployments.
docs/
Contains project documentation.
hack/
Contains files for development and Kubebuilder. This includes a kind.sh script that can be used to create a kind cluster with all pre-requisites for local testing.
helm/
Contains helm deployments, including the configuration files such as values.yaml.
Helm is the recommended method to install this project into your Kubernetes cluster.
internal/
Contains code that is used internally. This code is not externally importable.
internal/controller/
Contains the controllers.
Each controller is named after the Custom Resource Definition (CRD) it manages. Currently, this consists of the nodeset and the cluster CRDs.
3.2 - Cluster Control
Overview
This controller is responsible for managing and reconciling the Cluster CRD. A
CRD represents communication to a Slurm cluster via slurmrestd and auth/jwt.
This controller uses the Slurm client library.
Sequence Diagram
sequenceDiagram
autonumber
actor User as User
participant KAPI as Kubernetes API
participant CC as Cluster Controller
box Operator Internals
participant SCM as Slurm Client Map
participant SEC as Slurm Event Channel
end %% Operator Internals
note over KAPI: Handle CR Creation
User->>KAPI: Create Cluster CR
KAPI-->>CC: Watch Cluster CRD
CC->>+KAPI: Get referenced secret
KAPI-->>-CC: Return secret
create participant SC as Slurm Client
CC->>+SC: Create Slurm Client for Cluster
SC-->>-CC: Return Slurm Client Status
loop Watch Slurm Nodes
SC->>+SAPI: Get Slurm Nodes
SAPI-->>-SC: Return Slurm Nodes
SC->>SEC: Add Event for Cache Delta
end %% loop Watch Slurm Nodes
CC->>SCM: Add Slurm Client to Map
CC->>+SC: Ping Slurm Control Plane
SC->>+SAPI: Ping Slurm Control Plane
SAPI-->>-SC: Return Ping
SC-->>-CC: Return Ping
CC->>KAPI: Update Cluster CR Status
note over KAPI: Handle CR Deletion
User->>KAPI: Delete Cluster CR
KAPI-->>CC: Watch Cluster CRD
SCM-->>CC: Lookup Slurm Client
destroy SC
CC-)SC: Shutdown Slurm Client
CC->>SCM: Remove Slurm Client from Map
participant SAPI as Slurm REST API
3.3 - Develop
This document aims to provide enough information that you can get started with development on this project.
Getting Started
You will need a Kubernetes cluster to run against. You can use KIND to get a local cluster for testing, or run against your choice of remote cluster.
Note: Your controller will automatically use the current context in your
kubeconfig file (i.e. whatever cluster kubectl cluster-info shows).
Dependencies
Install KIND and Golang binaries for pre-commit hooks.
sudo apt-get install golang
make install
Pre-Commit
Install pre-commit and install the git hooks.
sudo apt-get install pre-commit
pre-commit install
Docker
Install Docker and configure rootless Docker.
After, test that your user account and communicate with docker.
docker run hello-world
Helm
Install Helm.
sudo snap install helm --classic
Skaffold
Install Skaffold.
curl -Lo skaffold https://storage.googleapis.com/skaffold/releases/latest/skaffold-linux-amd64 && \
sudo install skaffold /usr/local/bin/
If google-cloud-sdk is installed, skaffold is available as an additional component.
sudo apt-get install -y google-cloud-cli-skaffold
Kubernetes Client
Install kubectl.
sudo snap install kubectl --classic
If google-cloud-sdk is installed, kubectl is available as an additional component.
sudo apt-get install -y kubectl
Running on the Cluster
For development, all Helm deployments use a values-dev.yaml. If they do not
exist in your environment yet or you are unsure, safely copy the values.yaml
as a base by running:
make values-dev
Automatic
You can use Skaffold to build and push images, and deploy components using:
cd helm/slurm-operator/
skaffold run
NOTE: The skaffold.yaml is configured to inject the image and tag into the
values-dev.yaml so they are correctly referenced.
Operator
The slurm operator aims to follow the Kubernetes Operator pattern.
It uses Controllers, which provide a reconcile function responsible for synchronizing resources until the desired state is reached on the cluster.
Install CRDs
When deploying a helm chart with skaffold or helm, the CRDs defined in its
crds/ directory will be installed if not already present in the cluster.
Uninstall CRDs
To delete the Operator CRDs from the cluster:
make uninstall
WARNING: CRDs do not upgrade! The old ones must be uninstalled first so the new ones can be installed. This should only be done in development.
Modifying the API Definitions
If you are editing the API definitions, generate the manifests such as CRs or CRDs using:
make manifests
Slurm Version Changed
If the Slurm version has changed, generate the new OpenAPI spec and its golang client code using:
make generate
NOTE: Update code interacting with the API in accordance with the slurmrestd plugin lifecycle.
Running the operator locally
Install the operator’s CRDs with make install.
Launch the operator via the VSCode debugger using the “Launch Operator” launch task.
Because the operator will be running outside of Kubernetes and needs to
communicate to the Slurm cluster, set the following options in you Slurm helm
chart’s values.yaml:
debug.enable=truedebug.localOperator=true
If running on a Kind cluster, also set:
debug.disableCgroups=true
If the Slurm helm chart is being deployed with skaffold, run
skaffold run --port-forward --tail. It is configured to automatically
port-forward the restapi for the local operator to
communicate with the Slurm cluster.
If skaffold is not used, manually run
kubectl port-forward --namespace slurm services/slurm-restapi 6820:6820 for
the local operator to communicate with the Slurm cluster.
After starting the operator, verify it is able to contact the Slurm cluster by checking that the Cluster CR has been marked ready:
$ kubectl get --namespace slurm clusters.slinky.slurm.net
NAME READY AGE
slurm true 110s
See skaffold port-forwarding to learn how skaffold automatically detects which services to forward.
3.4 - NodeSet Controller
Overview
The nodeset controller is responsible for managing and reconciling the NodeSet CRD, which represents a set of homogeneous Slurm Nodes.
Design
This controller is responsible for managing and reconciling the NodeSet CRD. In addition to the regular responsibility of managing resources in Kubernetes via the Kubernetes API, this controller should take into consideration the state of Slurm to make certain reconciliation decisions.
Sequence Diagram
sequenceDiagram
autonumber
actor User as User
participant KAPI as Kubernetes API
participant NS as NodeSet Controller
box Operator Internals
participant SCM as Slurm Client Map
participant SEC as Slurm Event Channel
end %% Operator Internals
participant SC as Slurm Client
participant SAPI as Slurm REST API
loop Watch Slurm Nodes
SC->>+SAPI: Get Slurm Nodes
SAPI-->>-SC: Return Slurm Nodes
SC->>SEC: Add Event for Cache Delta
end %% loop Watch Slurm Nodes
note over KAPI: Handle CR Update
SEC-->>NS: Watch Event Channel
User->>KAPI: Update NodeSet CR
KAPI-->>NS: Watch NodeSet CRD
opt Scale-out Replicas
NS->>KAPI: Create Pods
end %% Scale-out Replicas
opt Scale-in Replicas
SCM-->>NS: Lookup Slurm Client
NS->>+SC: Drain Slurm Node
SC->>+SAPI: Drain Slurm Node
SAPI-->>-SC: Return Drain Slurm Node Status
SC-->>-NS: Drain Slurm Node
alt Slurm Node is Drained
NS->>KAPI: Delete Pod
else
NS->>NS: Check Again Later
end %% alt Slurm Node is Drained
end %% opt Scale-in Replicas
4 - Quickstart Guides
4.1 - Basic Quickstart
QuickStart Guide
Overview
This quickstart guide will help you get the slurm-operator running and deploy Slurm clusters to Kubernetes.
Install
Pre-Requiisites
Install the pre-requisite helm charts.
helm repo add prometheus-community
https://prometheus-community.github.io/helm-charts helm repo add metrics-server
https://kubernetes-sigs.github.io/metrics-server/ helm repo add bitnami
https://charts.bitnami.com/bitnami helm repo add jetstack
https://charts.jetstack.io helm repo update helm install cert-manager
jetstack/cert-manager \
--namespace cert-manager --create-namespace --set crds.enabled=true helm
install prometheus prometheus-community/kube-prometheus-stack \
--namespace prometheus --create-namespace --set installCRDs=trueSlurm Operator
Download values and install the slurm-operator from OCI package.
curl -L
https://raw.githubusercontent.com/SlinkyProject/slurm-operator/refs/tags/v0.1.0/helm/slurm-operator/values.yaml
\
-o values-operator.yaml helm install slurm-operator
oci://ghcr.io/slinkyproject/charts/slurm-operator \
--values=values-operator.yaml --version=0.1.0 --namespace=slinky
--create-namespace Make sure the cluster deployed successfully with:
kubectl --namespace=slinky get pods Output should be similar to:
NAME READY STATUS RESTARTS AGE
slurm-operator-7444c844d5-dpr5h 1/1 Running 0 5m00s
slurm-operator-webhook-6fd8d7857d-zcvqh 1/1 Running 0 5m00s Slurm Cluster
Download values and install a Slurm cluster from OCI package.
curl -L
https://raw.githubusercontent.com/SlinkyProject/slurm-operator/refs/tags/v0.1.0/helm/slurm/values.yaml
\
-o values-slurm.yaml helm install slurm
oci://ghcr.io/slinkyproject/charts/slurm \
--values=values-slurm.yaml --version=0.1.0 --namespace=slurm --create-namespaceMake sure the slurm cluster deployed successfully with:
kubectl --namespace=slurm get pods Output should be similar to:
NAME READY STATUS RESTARTS AGE slurm-accounting-0 1/1
Running 0 5m00s slurm-compute-debug-0 1/1 Running 0 5m00s slurm-controller-0 2/2
Running 0 5m00s slurm-exporter-7b44b6d856-d86q5 1/1 Running 0 5m00s
slurm-mariadb-0 1/1 Running 0 5m00s slurm-restapi-5f75db85d9-67gpl 1/1 Running 0
5m00s Testing
To test Slurm functionality, connect to the controller to use Slurm client commands:
kubectl --namespace=slurm exec -it
statefulsets/slurm-controller -- bash --login On the controller pod (e.g. host slurm@slurm-controller-0), run the following commands to quickly test Slurm is functioning:
sinfo srun hostname sbatch --wrap="sleep 60" squeueSee Slurm Commands for more details on how to interact with Slurm.
4.2 - QuickStart Guide for Google GKE
This quickstart guide will help you get the slurm-operator running and deploy Slurm clusters to GKE.
Setup
Setup a cluster on GKE.
gcloud container clusters create
slinky-cluster \
--location=us-central1-a \
--num-nodes=2 \
--node-taints "" \
--machine-type=c2-standard-16 Setup kubectl to point to your new cluster.
gcloud
container clusters get-credentials slinky-cluster Pre-Requisites
Install the pre-requisite helm charts.
helm repo add
prometheus-community https://prometheus-community.github.io/helm-charts helm
repo add kedacore https://kedacore.github.io/charts helm repo add metrics-server
https://kubernetes-sigs.github.io/metrics-server/ helm repo add bitnami
https://charts.bitnami.com/bitnami helm repo add jetstack
https://charts.jetstack.io helm repo update helm install cert-manager
jetstack/cert-manager \
--namespace cert-manager --create-namespace --set crds.enabled=true helm
install prometheus prometheus-community/kube-prometheus-stack \
--namespace prometheus --create-namespace --set installCRDs=trueSlurm Operator
Download values and install the slurm-operator from OCI package.
curl -L
https://raw.githubusercontent.com/SlinkyProject/slurm-operator/refs/tags/v0.1.0/helm/slurm-operator/values.yaml
\
-o values-operator.yaml helm install slurm-operator
oci://ghcr.io/slinkyproject/charts/slurm-operator \
--version 0.1.0 \
-f values-operator.yaml \
--namespace=slinky \
--create-namespace Make sure the cluster deployed successfully with:
kubectl
--namespace=slinky get pods Output should be similar to:
NAME READY STATUS RESTARTS
AGE slurm-operator-7444c844d5-dpr5h 1/1 Running 0 5m00s
slurm-operator-webhook-6fd8d7857d-zcvqh 1/1 Running 0 5m00s Slurm Cluster
Download values and install a Slurm cluster from OCI package.
curl -L
https://raw.githubusercontent.com/SlinkyProject/slurm-operator/refs/tags/v0.1.0/helm/slurm/values.yaml
\
-o values-slurm.yaml helm install slurm
oci://ghcr.io/slinkyproject/charts/slurm \
--version 0.1.0 \
-f values-slurm.yaml \
--namespace=slurm \
--create-namespace Make sure the slurm cluster deployed successfully with:
kubectl --namespace=slurm get pods Output should be similar to:
NAME READY STATUS RESTARTS
AGE slurm-accounting-0 1/1 Running 0 5m00s slurm-compute-debug-l4bd2 1/1 Running
0 5m00s slurm-controller-0 2/2 Running 0 5m00s slurm-exporter-7b44b6d856-d86q5
1/1 Running 0 5m00s slurm-mariadb-0 1/1 Running 0 5m00s
slurm-restapi-5f75db85d9-67gpl 1/1 Running 0 5m00s Testing
To test Slurm functionality, connect to the controller to use Slurm client commands:
kubectl --namespace=slurm exec \
-it statefulsets/slurm-controller -- bash --login On the controller pod (e.g. host slurm@slurm-controller-0), run the following commands to quickly test Slurm is functioning:
sinfo srun
hostname sbatch --wrap="sleep 60" squeue See Slurm Commands for more details on how to interact with Slurm.
4.3 - QuickStart Guide for Microsoft AKS
This quickstart guide will help you get the slurm-operator running and deploy Slurm clusters to AKS.
Setup
Setup a resource group on AKS
az group create --name
slinky --location westus2 Setup a cluster on AKS
az aks create \
--resource-group slinky \
--name slinky \
--location westus2 \
--node-vm-size Standard_D2s_v3 Setup kubectl to point to your new cluster.
az aks
get-credentials --resource-group slinky --name slinky Pre-Requisites
Install the pre-requisite helm charts.
helm repo add
prometheus-community https://prometheus-community.github.io/helm-charts helm
repo add kedacore https://kedacore.github.io/charts helm repo add metrics-server
https://kubernetes-sigs.github.io/metrics-server/ helm repo add bitnami
https://charts.bitnami.com/bitnami helm repo add jetstack
https://charts.jetstack.io helm repo update helm install cert-manager
jetstack/cert-manager \
--namespace cert-manager --create-namespace --set crds.enabled=true helm
install prometheus prometheus-community/kube-prometheus-stack \
--namespace prometheus --create-namespace --set installCRDs=trueSlurm Operator
Download values and install the slurm-operator from OCI package.
curl -L
https://raw.githubusercontent.com/SlinkyProject/slurm-operator/refs/tags/v0.1.0/helm/slurm-operator/values.yaml
\
-o values-operator.yaml
helm install slurm-operator oci://ghcr.io/slinkyproject/charts/slurm-operator \
--version 0.1.0 \
-f values-operator.yaml \
--namespace=slinky \
--create-namespace Make sure the cluster deployed successfully with:
kubectl
--namespace=slinky get pods Output should be similar to:
NAME READY STATUS RESTARTS
AGE slurm-operator-7444c844d5-dpr5h 1/1 Running 0 5m00s
slurm-operator-webhook-6fd8d7857d-zcvqh 1/1 Running 0 5m00s Slurm Cluster
Download values and install a Slurm cluster from OCI package.
curl -L
https://raw.githubusercontent.com/SlinkyProject/slurm-operator/refs/tags/v0.1.0/helm/slurm/values.yaml
\
-o values-slurm.yaml By default the values-slurm.yaml file uses standard for
controller.persistence.storageClass and
mariadb.primary.persistence.storageClass. You will need to update this value
to default to use AKS’s default storageClass.
helm install slurm
oci://ghcr.io/slinkyproject/charts/slurm \
--version 0.1.0 \
-f values-slurm.yaml \
--namespace=slurm \
--create-namespace Make sure the slurm cluster deployed successfully with:
kubectl --namespace=slurm get pods Output should be similar to:
NAME READY STATUS RESTARTS
AGE slurm-accounting-0 1/1 Running 0 5m00s slurm-compute-debug-l4bd2 1/1 Running
0 5m00s slurm-controller-0 2/2 Running 0 5m00s slurm-exporter-7b44b6d856-d86q5
1/1 Running 0 5m00s slurm-mariadb-0 1/1 Running 0 5m00s
slurm-restapi-5f75db85d9-67gpl 1/1 Running 0 5m00s Testing
To test Slurm functionality, connect to the controller to use Slurm client commands:
kubectl --namespace=slurm exec \
-it statefulsets/slurm-controller -- bash --login On the controller pod (e.g. host slurm@slurm-controller-0), run the following commands to quickly test Slurm is functioning:
sinfo srun
hostname sbatch --wrap="sleep 60" squeue See Slurm Commands for more details on how to interact with Slurm.