Concepts related to slurm-operator internals and design.
This is the multi-page printable view of this section. Click here to print.
Concepts
- 1: Architecture
- 2: Cluster Controller
- 3: NodeSet Controller
- 4: Cluster CRD
- 5: NodeSet CRD
- 6: Slurm
1 - Architecture
Overview
This document describes the high-level architecture of the Slinky
slurm-operator.
Operator
The following diagram illustrates the operator, from a communication perspective.

The slurm-operator follows the Kubernetes operator
pattern.
Operators are software extensions to Kubernetes that make use of custom resources to manage applications and their components. Operators follow Kubernetes principles, notably the control loop.
The slurm-operator has one controller for each Custom Resource Definition
(CRD) that it is responsible to manage. Each controller has a control loop where
the state of the Custom Resource (CR) is reconciled.
Often, an operator is only concerned about data reported by the Kubernetes API.
In our case, we are also concerned about data reported by the Slurm API, which
influences how the slurm-operator reconciles certain CRs.
Slurm
The following diagram illustrates a containerized Slurm cluster, from a communication perspective.

For additional information about Slurm, see the slurm docs.
Hybrid
The following hybrid diagram is an example. There are many different configurations for a hybrid setup. The core takeaways are: slurmd can be on bare-metal and still be joined to your containerized Slurm cluster; external services that your Slurm cluster needs or wants (e.g. AD/LDAP, NFS, MariaDB) do not have to live in Kubernetes to be functional with your Slurm cluster.

Autoscale
Kubernetes supports resource autoscaling. In the context of Slurm, autoscaling Slurm compute nodes can be quite useful when your Kubernetes and Slurm clusters have workload fluctuations.

See the autoscaling guide for additional information.
Directory Map
This project follows the conventions of:
api/
Contains Custom Kubernetes API definitions. These become Custom Resource Definitions (CRDs) and are installed into a Kubernetes cluster.
cmd/
Contains code to be compiled into binary commands.
config/
Contains yaml configuration files used for kustomize deployments.
docs/
Contains project documentation.
hack/
Contains files for development and Kubebuilder. This includes a kind.sh script that can be used to create a kind cluster with all pre-requisites for local testing.
helm/
Contains helm deployments, including the configuration files such as values.yaml.
Helm is the recommended method to install this project into your Kubernetes cluster.
internal/
Contains code that is used internally. This code is not externally importable.
internal/controller/
Contains the controllers.
Each controller is named after the Custom Resource Definition (CRD) it manages. Currently, this consists of the nodeset and the cluster CRDs.
2 - Cluster Controller
Overview
This controller is responsible for managing and reconciling the Cluster CRD. A
CRD represents communication to a Slurm cluster via slurmrestd and auth/jwt.
This controller uses the Slurm client library.
Sequence Diagram
sequenceDiagram
autonumber
actor User as User
participant KAPI as Kubernetes API
participant CC as Cluster Controller
box Operator Internals
participant SCM as Slurm Client Map
participant SEC as Slurm Event Channel
end %% Operator Internals
note over KAPI: Handle CR Creation
User->>KAPI: Create Cluster CR
KAPI-->>CC: Watch Cluster CRD
CC->>+KAPI: Get referenced secret
KAPI-->>-CC: Return secret
create participant SC as Slurm Client
CC->>+SC: Create Slurm Client for Cluster
SC-->>-CC: Return Slurm Client Status
loop Watch Slurm Nodes
SC->>+SAPI: Get Slurm Nodes
SAPI-->>-SC: Return Slurm Nodes
SC->>SEC: Add Event for Cache Delta
end %% loop Watch Slurm Nodes
CC->>SCM: Add Slurm Client to Map
CC->>+SC: Ping Slurm Control Plane
SC->>+SAPI: Ping Slurm Control Plane
SAPI-->>-SC: Return Ping
SC-->>-CC: Return Ping
CC->>KAPI: Update Cluster CR Status
note over KAPI: Handle CR Deletion
User->>KAPI: Delete Cluster CR
KAPI-->>CC: Watch Cluster CRD
SCM-->>CC: Lookup Slurm Client
destroy SC
CC-)SC: Shutdown Slurm Client
CC->>SCM: Remove Slurm Client from Map
participant SAPI as Slurm REST API
3 - NodeSet Controller
Overview
The nodeset controller is responsible for managing and reconciling the NodeSet CRD, which represents a set of homogeneous Slurm Nodes.
Design
This controller is responsible for managing and reconciling the NodeSet CRD. In addition to the regular responsibility of managing resources in Kubernetes via the Kubernetes API, this controller should take into consideration the state of Slurm to make certain reconciliation decisions.
Sequence Diagram
sequenceDiagram
autonumber
actor User as User
participant KAPI as Kubernetes API
participant NS as NodeSet Controller
box Operator Internals
participant SCM as Slurm Client Map
participant SEC as Slurm Event Channel
end %% Operator Internals
participant SC as Slurm Client
participant SAPI as Slurm REST API
loop Watch Slurm Nodes
SC->>+SAPI: Get Slurm Nodes
SAPI-->>-SC: Return Slurm Nodes
SC->>SEC: Add Event for Cache Delta
end %% loop Watch Slurm Nodes
note over KAPI: Handle CR Update
SEC-->>NS: Watch Event Channel
User->>KAPI: Update NodeSet CR
KAPI-->>NS: Watch NodeSet CRD
opt Scale-out Replicas
NS->>KAPI: Create Pods
end %% Scale-out Replicas
opt Scale-in Replicas
SCM-->>NS: Lookup Slurm Client
NS->>+SC: Drain Slurm Node
SC->>+SAPI: Drain Slurm Node
SAPI-->>-SC: Return Drain Slurm Node Status
SC-->>-NS: Drain Slurm Node
alt Slurm Node is Drained
NS->>KAPI: Delete Pod
else
NS->>NS: Check Again Later
end %% alt Slurm Node is Drained
end %% opt Scale-in Replicas
4 - Cluster CRD
5 - NodeSet CRD
6 - Slurm
Slurm is an open source, fault-tolerant, and highly scalable cluster management and job scheduling system for large and small Linux clusters. Slurm requires no kernel modifications for its operation and is relatively self-contained. As a cluster workload manager, Slurm has three key functions. First, it allocates exclusive and/or non-exclusive access to resources (compute nodes) to users for some duration of time so they can perform work. Second, it provides a framework for starting, executing, and monitoring work (normally a parallel job) on the set of allocated nodes. Finally, it arbitrates contention for resources by managing a queue of pending work. Optional plugins can be used for accounting, advanced reservation, gang scheduling (time sharing for parallel jobs), backfill scheduling, topology optimized resource selection, resource limits by user or bank account, and sophisticated multifactor job prioritization algorithms.
Architecture
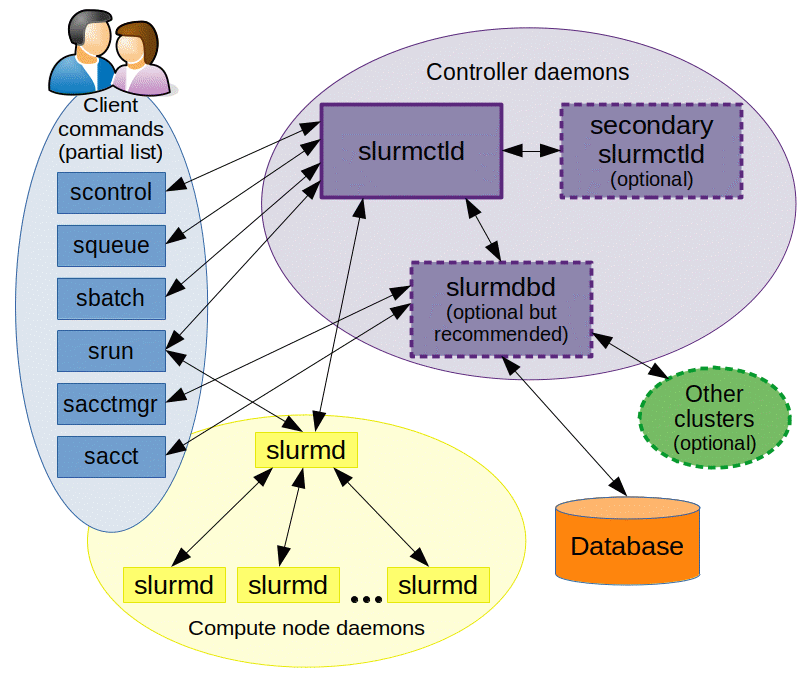
See the Slurm architecture docs for more information.